
近年来,相控阵全聚焦技术因具有成像分辨率高、检测范围大的优点,在焊缝缺陷检测方面得到广泛应用[1]。传统全聚焦成像技术成像路径单一,难以精确、完整地重构常见的面积型缺陷和裂纹的形状和角度[2]。为解决该问题,研究人员根据声束在工件内部传播的特点提出了多模式全聚焦法[3-4],该方法利用声束的波形转换和不同的传播路径,可获得更多缺陷信息,有效提高缺陷检出率和检测效率[5-6]。但不同模式的全聚焦对于同一缺陷进行成像可能会产生成像错位、伪影等干扰,难以准确分析。而将多个全聚焦视图融合成一张图像,能减少数据量进而提高信息量,优化成像结果,有助于检测人员对缺陷进行综合判读[7]。但随着融合模式数的增加,噪声和结构性伪影也会一并叠加在融合图像中,破坏成像质量[8]。
为解决多模式融合的伪影叠加问题,提出基于直接视图的自适应多模式全聚焦成像方法,利用直接模式下全聚焦图像中缺陷的位置信息,对缺陷区域进行自适应定位,并对其进行精准多模式融合,降低结构性伪影对成像结果的影响,提高多模式融合的成像质量。文章介绍了全聚焦多模式融合成像的基本原理,与自适应区域融合算法流程,然后进行验证试验与分析,最后进行总结与展望。
1. 全聚焦检测原理概述
1.1 相控阵多模式融合成像原理
超声波声束在多层介质的界面交界处因常发生波形转换、反射和折射而具有不同传播模式和传播路径,进而可以获得大量超声图像[9]。根据超声波是否经过底面反射,可以将全聚焦模式分为直接式、半跨越式和全跨越式(见图1);再考虑声束在交界面处发生的波形转换,可以得到一共21种不同的模式,全聚焦成像的21种视图如表1所示。

| 模式 | 视图 |
|---|---|
| 直接式 | TT,TL,LL |
| 半跨越式 | TT-T,TT-L,LL-L,LL-T,LT-L,LT-T,TL-T,TL-L |
| 全跨越式 | LL-LL,LL-LT,LL-TL,LL-TT,LT-TT,LT-LT,LT-TL,TL-TT,TL-TL,TT-TT |
利用多模式全聚焦成像时,关注区域中任意成像点的幅值Im(x,z)可表示为

式中:m为全聚焦成像模式;(x,z)为成像点坐标;N为相控阵探头的阵元数;,为模式m中针对反射点(x,z),i阵元发射j阵元接收的超声波幅值;,为声束传播最短时间;h(x)为希尔伯特变换。
常见的融合方式有最大值融合和累加融合,其表达式分别为

式中:M为要融合的模式数。
以上两种模式融合方法,计算简单,不易丢失有用信息。但随着融合模式数量增加,各模式中的噪声和结构性伪影也会叠加,使融合后全聚焦图像的信噪比显著下降。且由于全聚焦成像本身的计算量巨大,融合模式数量的增加会大幅提高计算成本。因此要根据声束传播路径及需要检测的缺陷类型,选择合适数量和类型的模式进行融合成像,这对降低算法计算量,提高融合后图像信噪比有着重要的意义[10]。
焊缝中常见的未熔合、裂纹等面积型缺陷,存在一定的方向性,单一模式下全聚焦图像对某些角度敏感,但一旦超过此角度范围,重构缺陷质量将大幅降低,进而影响检测人员对缺陷性质的判断。而不同全聚焦模式下,声束传播路径不同,对于方向性缺陷的最佳检测角度也不同,故选择合适的重构模式,可以提高缺陷检出率并还原缺陷真实轮廓[11]。
1.2 相位相干成像原理
希尔伯特变换(Hilbert transform)是一个对函数产生定义域相同的函数的线性算子[12],对于任意实信号x(t),其希尔伯特变换xh(t)被定义为原实信号与函数的卷积,即

式中:*代表卷积;τ为积分变量。
希尔伯特变换相当于把信号的正频部分移相-90°,负频部分移相90°。故经过希尔伯特变换后,可将实信号x(t)构造为复信号z(t),也称z(t)为原实信号x(t)的解析信号,即

式中:j为虚数单位。
由式(5)可知解析信号z(t)在复平面上的模和角度分别代表原信号x(t)的瞬时幅值A(t)和瞬时相位ϕ(t),即

矢量相干因子(VCF)是一种将信号瞬时相位视作单位圆上的随机变量,复平面的环形矢量如图2所示,其平均矢量和的模可以反映相角的一致程度[13-15]。所有相位越相近则指向性越明显,平均矢量和的模越大;当相位分布混乱,则平均矢量和的模趋近于0,矢量相干因子被定义为

式中:,,,,;i为发射阵元编号;j为接收阵元编号。
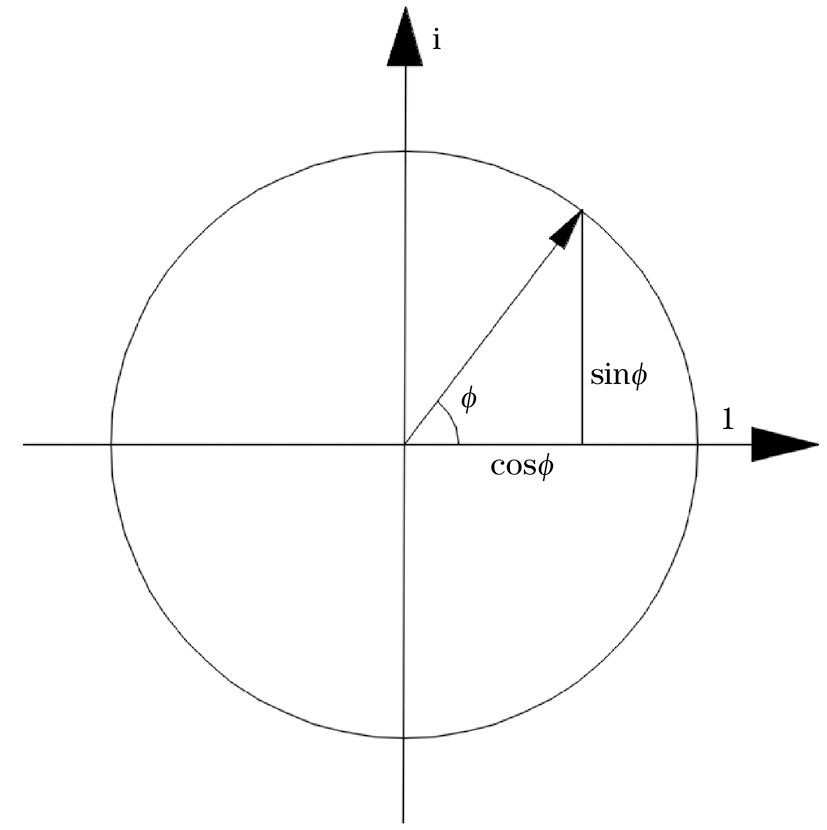
一般来说,当焦点处存在反射体时,各阵元接收到来自该焦点的信号,其相位分布是趋于一致的。因此可以根据式(8)计算各焦点的平均矢量和的模,并且该模值仅代表了焦点处的相位一致性而忽略了声程、声波幅值等因素的影响,所以更加适合作为缺陷的概率值。同时若以矢量相干因子作为权值对模式m的全聚焦图像中的每个像素幅值进行加权处理,可获得新振幅,从而能够有效抑制全聚焦图像中的背景噪声,改善图像信噪比,即

2. 算法及图像分析功能实现
2.1 算法流程
缺陷定位流程图如图3所示,对不同模式全聚焦图像进行分析,发现相较于半跨越式和全跨越式,直接式全聚焦声束传播路径更短,更不易出现结构型伪影。且直接式对方向性缺陷的衍射信号的捕捉能力更强,可以实现缺陷的精确定位。根据这些特性,文章提出一种基于直接视图的自适应多模融合方法,先基于直接视图对缺陷进行区域定位,再针对该区域进行针对性多模式融合,过滤大部分由叠加融合带来的噪声和结构性伪影,具体处理流程如下。

(1)根据相位相干原理,由式(8)计算TT模式下成像区域的矢量相干因子矩阵V(x,z),由1.2节分析,可将该矩阵等效为成像区域的缺陷概率分布矩阵。为进一步确定缺陷区域,需设定一个概率阈值T,当某点矢量相干因子的值大于阈值T时认为该点存在反射体,并认为以该点为中心,r为边长的矩形区域内可能存在缺陷,标记该区域。当遍历完V(x,z)所有点后,即可确定所有缺陷可能存在区域。得到定位矩阵P(x,z),该矩阵除了定位区域的元素值为1,其他区域的元素值均为0。
文章中设置概率阈值T=0.7,r=6 mm。
(2)根据各模式的最佳检测角度选择合适的模式进行多模式融合。文章以横波55°作为入射声束角度,选择TT,TT-L,TT-T,TT-TT四种模式作为融合模式,涵盖的最佳检测角度为-60°~60°。
(3)根据定位矩阵,计算定位区间内的全聚焦图像数据,即

(4)利用最大值多模融合原理,结合由步骤(1)计算的TT模式下的矢量相干因子矩阵对各模式全聚焦图像进行自适应区域的加权融合,降低背景噪声,即

通过以上步骤对多模式全聚焦图像进行处理,即可实现对方向性缺陷的有效重构以及对背景噪声和结构性伪影的滤除。
2.2 图像质量评价指标
对比度噪声比(CNR)是一种评价图像中对比度和噪声的指标,其根据全聚焦图像中缺陷区域和非缺陷区域的像素均值和标准差衡量目标缺陷与背景噪声的对比度,其表达式为[16]

式中:μ-6 dB为缺陷区域的像素均值;μBackground为背景区域的像素均值;σBackground为背景区域的标准差。
3. 试验与分析
为验证多模式自适应区域融合方法的优化效果,制作一个厚度为25 mm的碳钢焊板,其横波声速为ct=3 230 m·s-1,纵波声速为cl=5 900 m·s-1,焊缝中预埋有一个气孔缺陷和一个夹渣缺陷。并且制作了深度为10 mm,取向角度分别为-45°,-30°,0°,30°,45°,长度为6 mm,宽度为1 mm的人工刻槽模拟裂纹,人工刻槽碳钢试件实物如图4所示。

试验采用的探头型号为5L64-0.6×10,配套的楔块型号为SC7-N55S-H(见图5),楔块声速cw为2 337 m·s-1。

相控阵采集系统选择广东汕头的CTS-PA22T1型相控阵全聚焦实时3D超声成像系统,并使用其配套软件采集FMC(全矩阵捕获)数据。
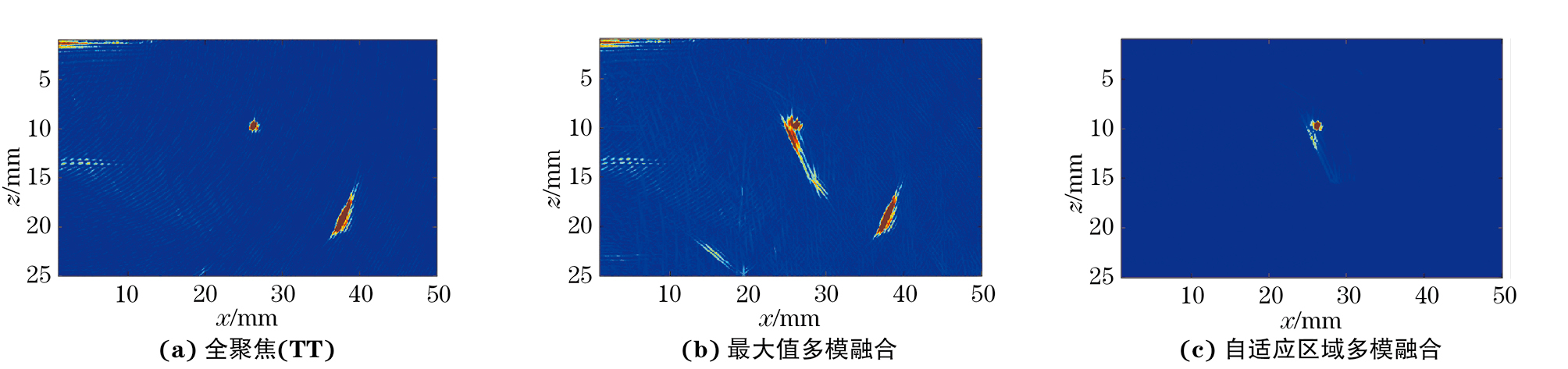
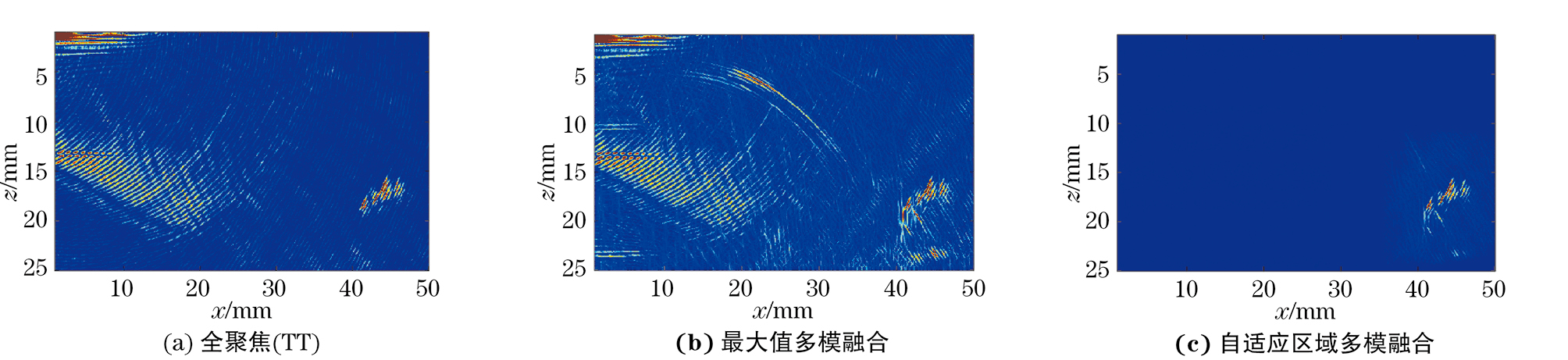
利用相控阵检测系统采集到的FMC数据,采用MATLAB软件的多模式全聚焦算法计算处理,得到TT,TT-T,TT-L,TT-TT四种模式的全聚焦图像。采用笔者所提算法对这四种模式进行融合成像,其过程如图6所示。
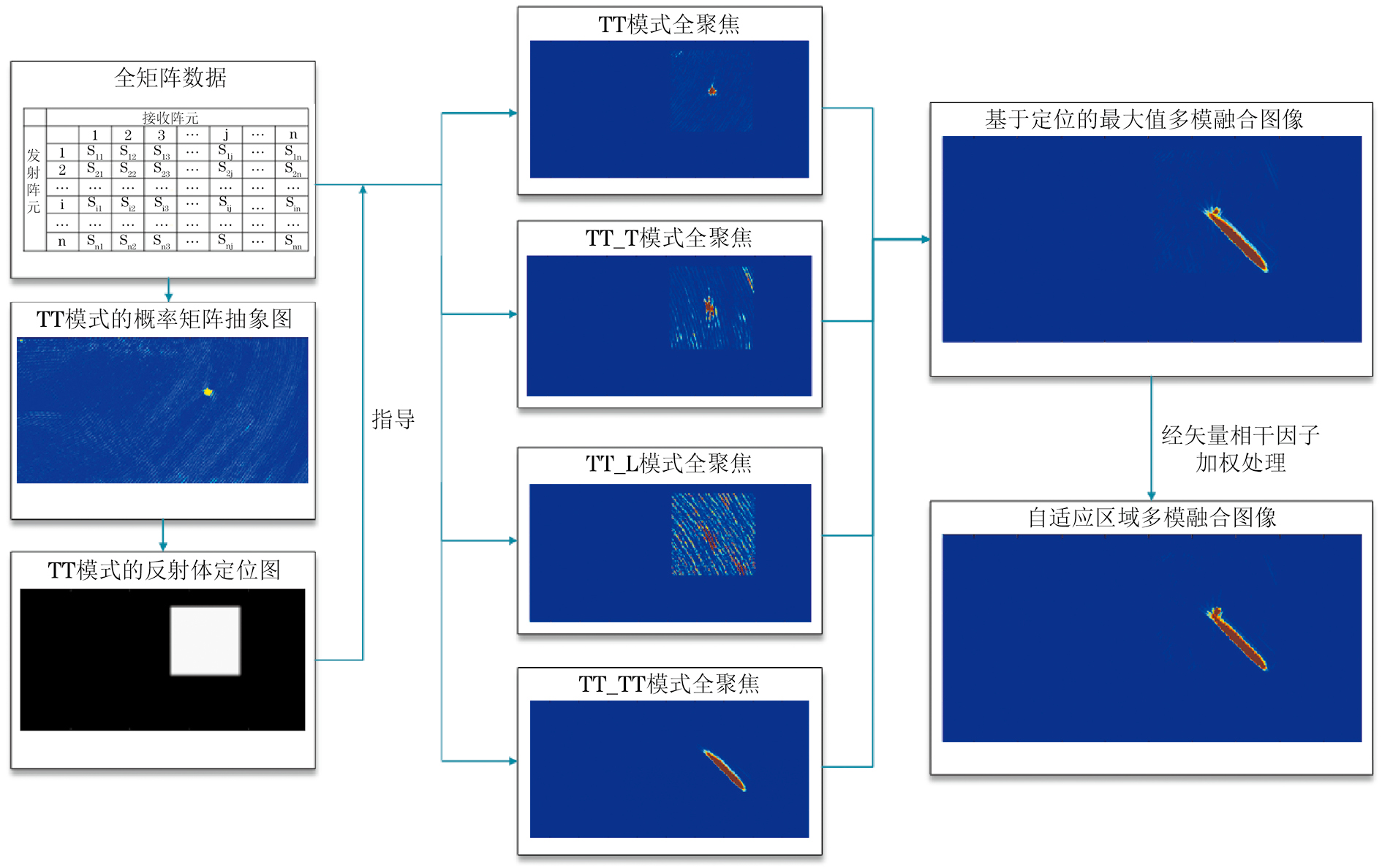
由图6可见,当刻槽倾角为-45°时,TT-TT模式的重构能力最强。模式TT尽管无法对刻槽形状进行完整重构但可以捕捉到该刻槽上端的衍射信号,且在该模式下几乎没有结构型伪影的干扰,因此可以根据衍射信号的信息对缺陷进行准确定位,这与上文分析结果一致。
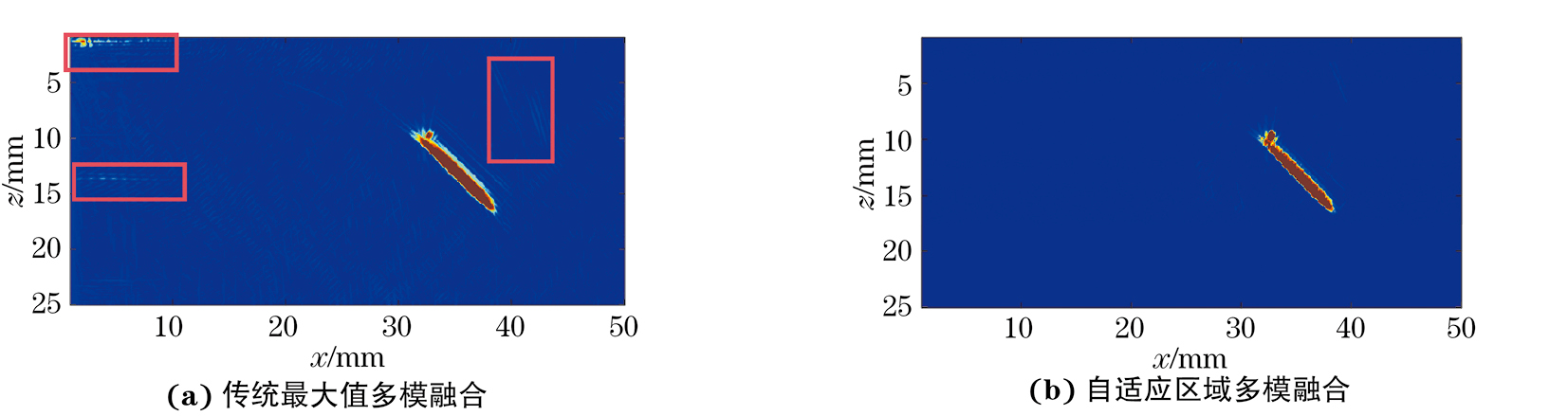
对-45°刻槽的TT、TT-T、TT-L、TT-TT四种模式,分别进行传统的最大值多模融合和自适应区域多模融合,其结果如图7所示,比较可知多模式融合技术的确可以对缺陷形状进行完整重构,极大程度地利用了不同全聚焦模式下的缺陷有效信息。通过自适应区域融合处理后的缺陷重构能力不仅没有下降,且图像信噪比和图像质量都有明显提高,如图7(a)中红框内的噪声和伪影都被消除。同时由于该算法仅对定位区域内的部分进行全聚焦计算,所以减少了全聚焦部分的计算量,自适应区域多模融合在全聚焦部分的计算时间上比传统最大值多模融合的时间减少了50.3%,并且随着加入融合的模式数量的增加,此算法计算量减少的优势越明显。
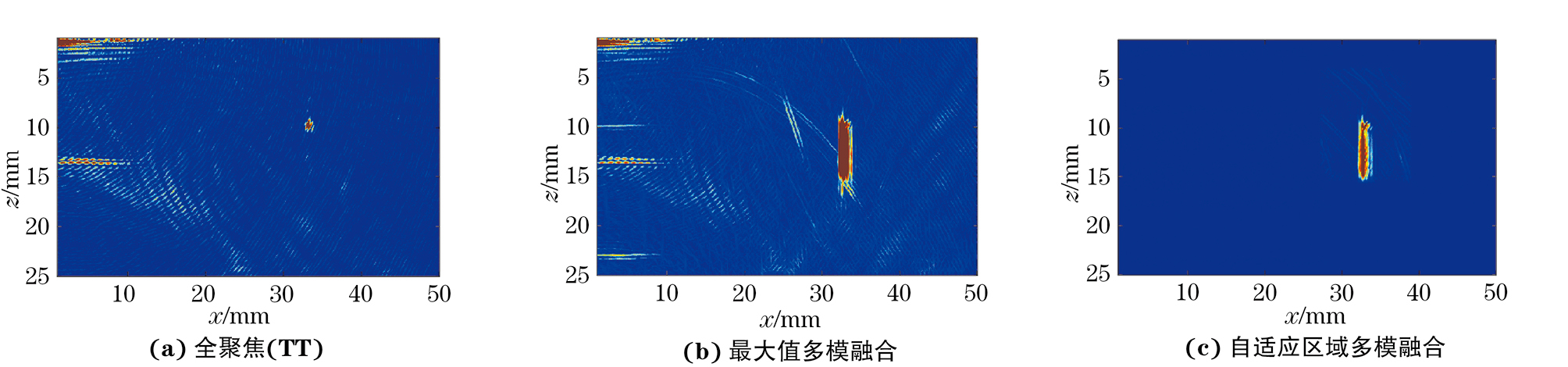
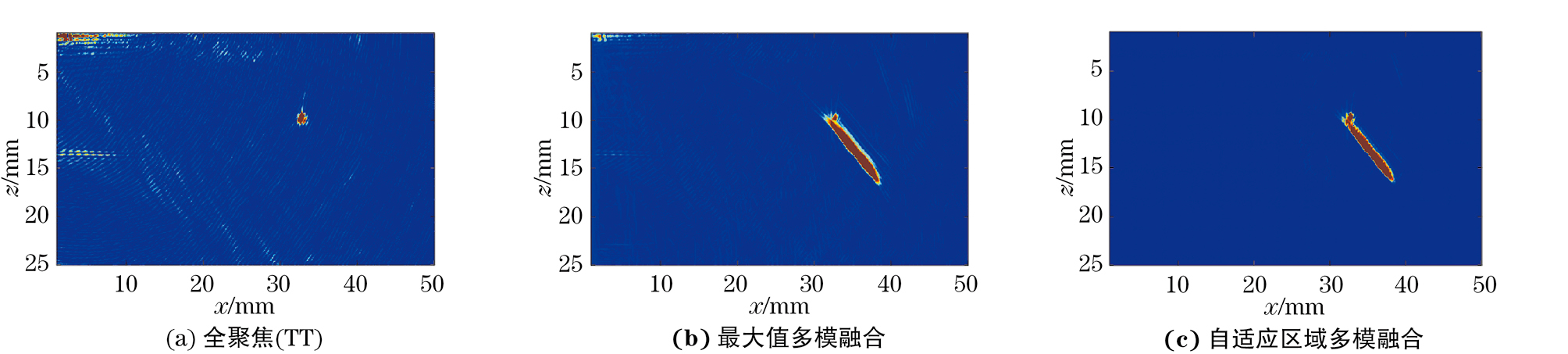
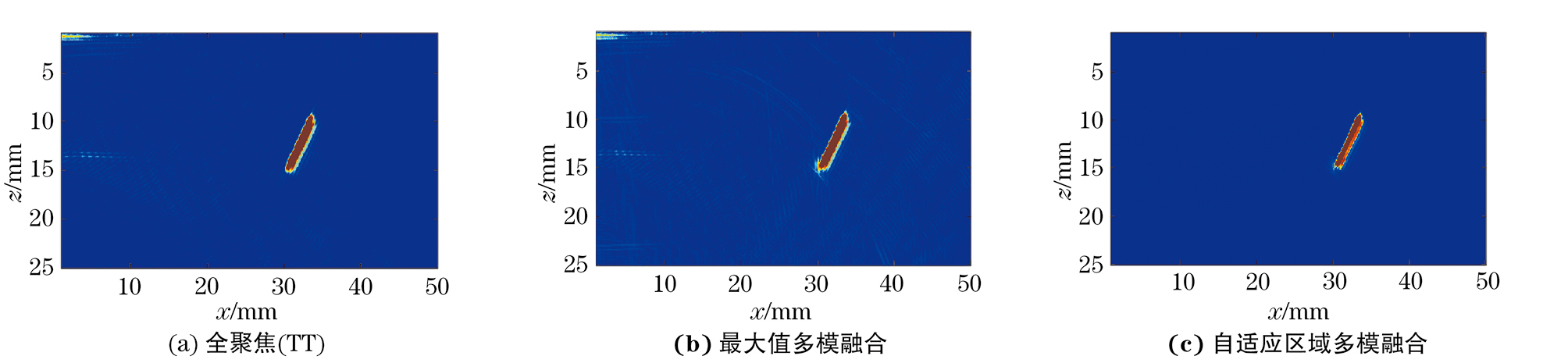
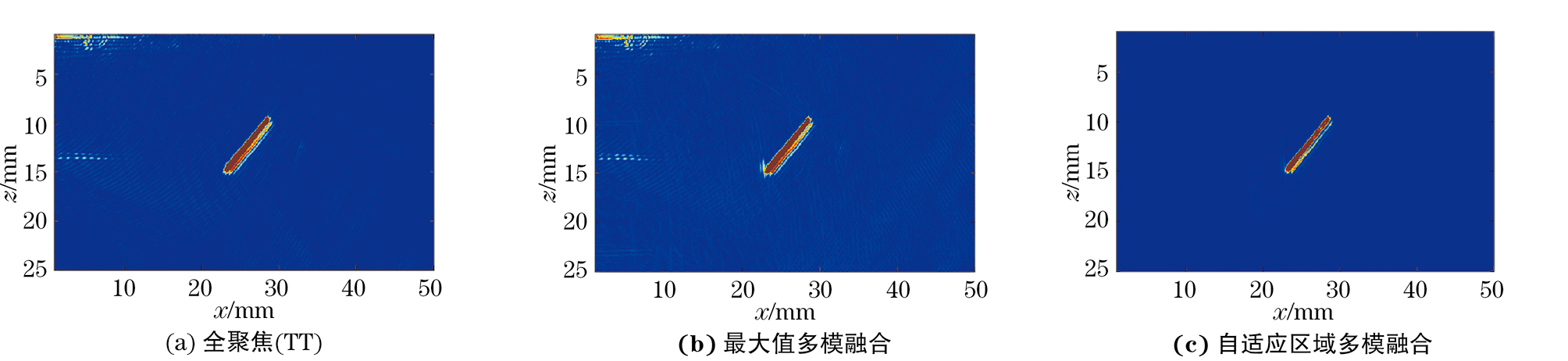
不同缺陷的TT模式全聚焦图像,基于TT、TT-T、TT-L、TT-TT四种模式的最大值多模融合图像和基于TT、TT-T、TT-L、TT-TT四种模式的自适应区域多模融合图像如图8~14所示。由图8~12可知,最大值多模融合图像中存在明显的背景噪声以及结构性伪影的干扰,通过自适应区域融合方法处理后,融合图像的信噪比有了显著的提高。分析图13,14可知,焊缝存在上下余高且结构复杂,故多模式融合图像中结构性伪影较多,图像信噪比较差,经过处理后,大部分结构性伪影被滤除。

| 缺陷角度/(°) | 最大值多模融合 | 自适应区域多模融合 | ||
|---|---|---|---|---|
| 长度误差/% | 宽度误差/% | 长度误差/% | 宽度误差/% | |
| -30 | 15.6 | -7.33 | -3.30 | -15.13 |
| -45 | 14.9 | 10.31 | -10.73 | -30.70 |
| 0 | 12.4 | 39.00 | 3.03 | 31.00 |
| 30 | -3.95 | 20.37 | -6.97 | -22.05 |
| 45 | -7.54 | -10.3 | -8.13 | -19.38 |
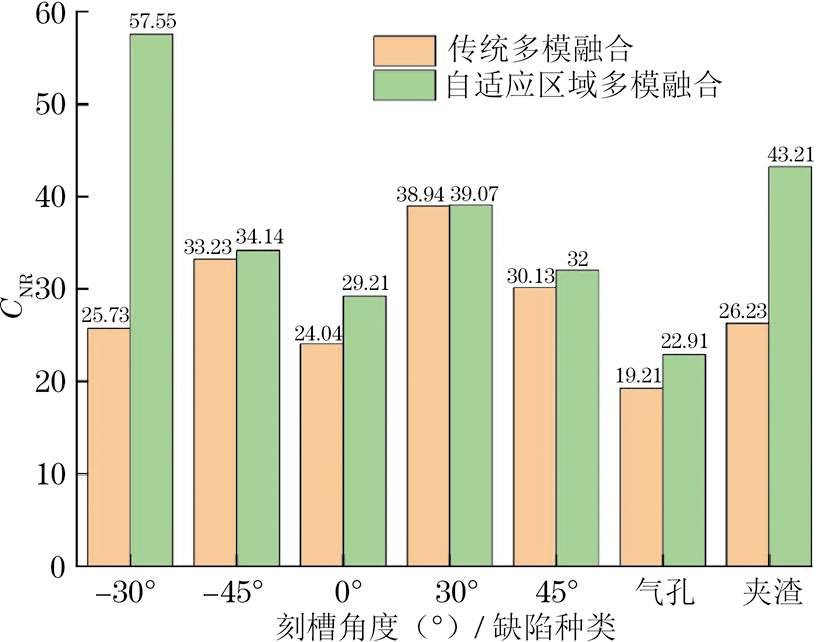
由表2和图8~15中显示的检测结果可以看出,与传统的最大值全聚焦多模融合算法相比较,经过自适应区域融合方法处理后,图像对比度噪声比得到明显提升,伪影和噪声几乎完全被滤除;且自适应区域融合对缺陷的定量精度与传统多模式融合方法能力相当;自适应区域多模融合的CNR平均高于传统多模融合方法约34.06%,即有着更高的成像质量。
4. 无损检测挂证网结语
所提方法在传统最大值全聚焦多模式融合成像算法的理论基础上,结合相位相干原理,利用TT直接模式下的全聚焦成像视图中的缺陷物理信息,提出了自适应多模式成像方法。与传统全聚焦成像算法和最大值多模融合成像算法相比,文章所提的多模融合成像方法进一步考虑了缺陷的位置信息,对非缺陷区域的结构性伪影和噪声的干扰实现了有效抑制,较大地提升了图像的对比度噪声比。同时,由于文章考虑了缺陷的位置信息,只叠加和融合在定位区域内部的全聚焦图像,因而与最大值多模融合方法相比,文章所提方法减少了全聚焦成像的计算量。
