
CFRP-PMI夹层结构复合材料具有轻质、高强度、良好的耐疲劳性和优异的抗冲击性等优点而被广泛应用在航空航天、风力发电、船舶制造等领域[1]。然而,这些复合材料在服役期间不可避免地会产生各种形式的损伤,如基体开裂、基体/纤维分层、纤维断裂、蒙皮/夹芯脱黏、夹芯损伤等[2]。损伤的积累不仅会降低材料的力学性能还会引发整体结构的失效,进而造成较大的经济损失。因此,准确识别CFRP-PMI夹层结构复合材料的损伤对于确保结构安全性和可靠性具有非常重要的意义[3]。近年来,人工智能的快速发展为解决这一问题提供了一种新思路。相关学者们开发了多种基于声发射技术(Acoustic emission,AE)来评估复合材料损伤程度的方法。尤其是将声发射技术与人工智能相结合的技术开始在众多领域展现出强大的潜力[4-6],特别是在碳纤维增强复合材料(CFRP)和泡沫组成的夹层结构失效检测评估领域。
首先通过格拉姆角场(Gramian angular summation field,GASF)将一维时间序列数据转化为二维图像数据来增强数据的特征表达,并将其作为视觉转换器(Vision transformer,ViT)模型的输入,然后通过ViT模型对二维数据进行分类,并在ViT模型中引入了特征融合模块(Hierarchical feature fusion,HFF)来提高特征表达,进而提高模型的分类准确率。
1. 单一损伤试验设计和方法
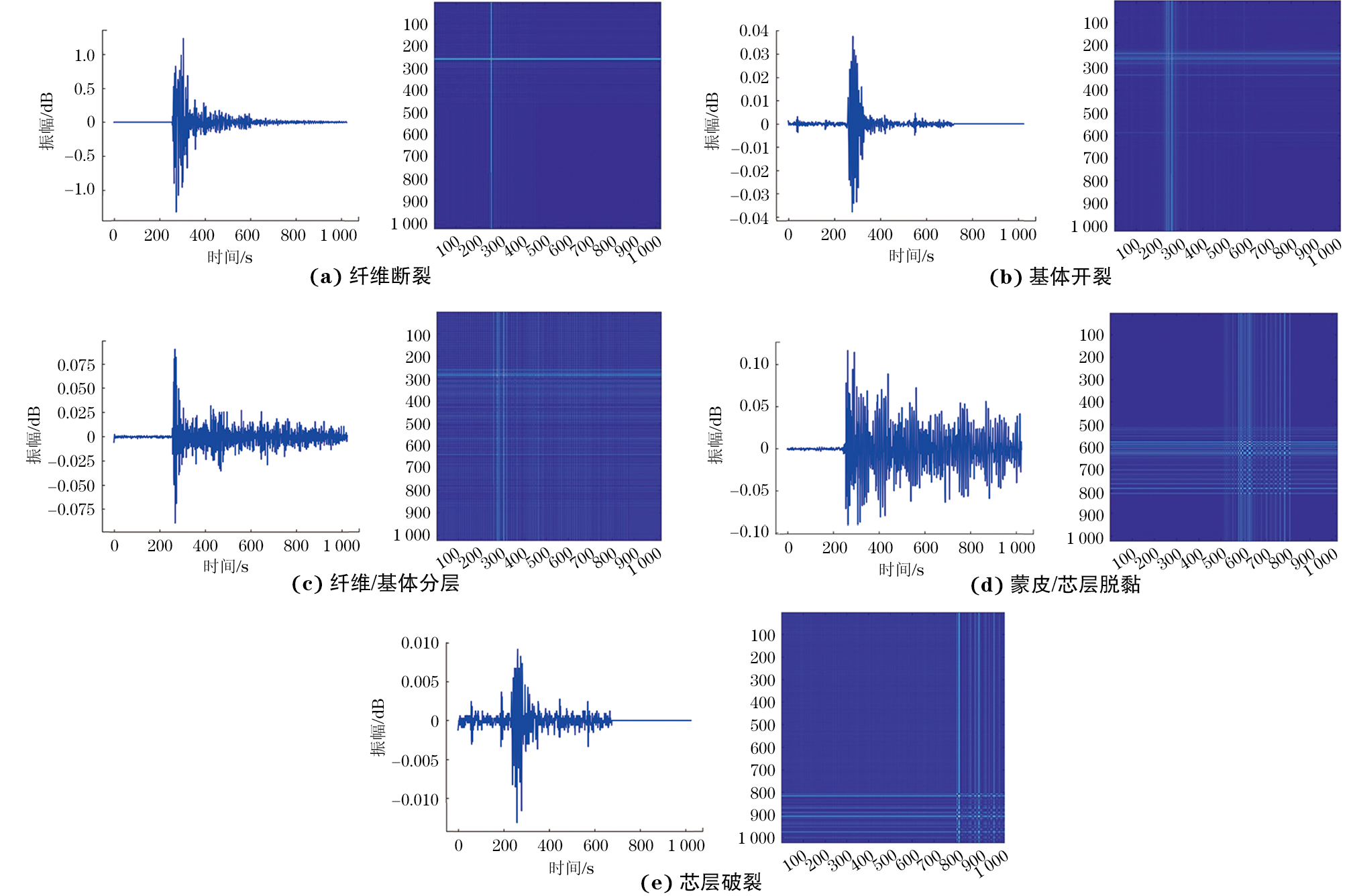
在大多数研究中,基体开裂、纤维断裂、基体/纤维分层、蒙皮/芯层脱黏以及芯层破裂为主要的复合材料损伤模式[2]。文章为利用深度学习方法将复合材料的损伤模式进行分类,设计了纤维束拉伸试验、基体拉伸试验、基体/纤维分层试验、蒙皮/芯层脱黏试验和泡沫芯三点弯曲试验,以获取CFRP-PMI夹层材料中基体开裂、纤维断裂、基体/纤维分层、蒙皮/芯层脱黏以及芯层破裂的单一损伤数据,具体如下。
碳纤维束拉伸试件的长×宽为45 mm×3 mm,利用SEM测试仪类型的原位拉伸机拉伸样本,并使用AE传感器接收AE信号,试验现场如图1所示(图中WD传感器为宽频带传感器)。以5 mm·min−1的拉伸速率拉伸试件直至断裂,观察并记录失效过程中的损伤模式以及试验现象。

根据GB/T 2567—2008《树脂浇铸体性能试验方法》对环氧树脂基体进行拉伸试验,基体试件为哑铃型环氧树脂浇注体,尺寸(长×宽×高,下同)为250.0 mm×25.0 mm×2.5 mm。使用岛津AG-X电子万能试验机拉伸试件,AE传感器在拉伸过程中接收AE信号,试验现场如图2所示。以5 mm·min−1的拉伸速率拉伸基体直至断裂,观察并记录失效过程中的损伤模式以及试验现象。

根据ASTM D 5528-13Standard test method for mode i interlaminar fracture toughness of unidirectional fiber-reinforced polymer matrix composites标准对尺寸为175 mm×25 mm×4 mm的碳纤维层合板进行分层试验。试件中插入尺寸为55 mm×25 mm×40 µm的聚四氟乙烯(PTFE)膜作为预制分层,一对铰链被粘贴于预制损伤的一端。然后向铰链施加拉伸载荷进行分层试验,AE传感器在加载过程中接收AE信号,试验现场如图3所示。以1 mm·min−1的拉伸速率拉伸碳纤维层合板直至其完全分层,观察并记录失效过程中的损伤模式以及试验现象。

根据ASTM D 5528-13 标准对尺寸为178.00 mm×20.00 mm×22.04 mm的CFRP-PMI夹层试件进行分层试验。试件中插入尺寸为55 mm×25 mm×40 µm的聚四氟乙烯(PTFE)膜作为预制分层,一对铰链被粘贴于预制损伤的一端。然后向铰链施加拉伸载荷进行分层试验,AE传感器在加载过程中接收AE信号,试验现场如图4所示。以1 mm·min−1的拉伸速率拉伸夹层试件直至其完全分层,观察并记录失效过程中的损伤模式以及试验现象。

根据ASTM D 790-03Standard test methods for flexural properties of unreinforced and reinforced plastics and electrical insulating materials标准对尺寸为200 mm×100 mm×22 mm的PMI泡沫芯进行三点弯曲试验,使用SANS万能试验机对试件进行加载,AE传感器在加载过程中接收AE信号,试验现场如图5所示。以1 mm·min−1的加载速率弯曲泡沫芯直至试件断裂,观察并记录失效过程中的损伤模式以及试验现象。

2. 理论基础
2.1 格拉姆角场
格拉姆角场(Gramian angular summation field,GASF)是一种使用笛卡尔坐标系将一维时间序列数据转化为二维图像的方法[7]。其可以捕捉到时间序列中的动态特征,保留原始信号中的关键信息,并提供简单直观的视觉显示。该方法将时间序列中的数据点两两组合,计算它们之间的夹角余弦,并将结果表示为图像的像素值。这种转换可以帮助捕捉时间序列数据中的动态和周期性特征。假定原始时间序列有n个值,,,,,,并且该序列被归一化到[-1,1]之间,表示为,,,,,为标准化时间序列的值。将数据映射到极坐标系中为,可表示为

式中:max,min为最大,最小函数。
时间序列以极坐标表示时,映射到角度φi,时间戳ti映射到半径ri,则有

式中:时间戳ti将区间[0,1]划分为N等份,从而使极坐标系的跨度正则化。
将一维数据映射到极坐标系后,每个时间点的相关性由三角和来确定,其表达式为

式中:为缩放后的时间序列;I为对应每个时间点的位置索引。
2.2 Vision transformer模型
Vision transformer(ViT)是一种可以直接应用于图像分类任务的深度学习模型[8],整体架构如图6所示(图中MLP为多层感知机)。其尽可能地遵循Transformer的原始架构。为了使其能够处理二维图像数据,图像被线性化为一组平坦的二维补丁(patch),其中c为通道数,(h,w)为原始图像的分辨率,(p,p)为每个图像块的分辨率。因此,Transformer的有效序列长度,然后为嵌入补丁添加位置嵌入(PE)P向量,作为标准的一维位置嵌入,X和P的维度为模型维度dmodel,其表达式为

式中:pos为patch的位置;i为patch的当前尺寸。
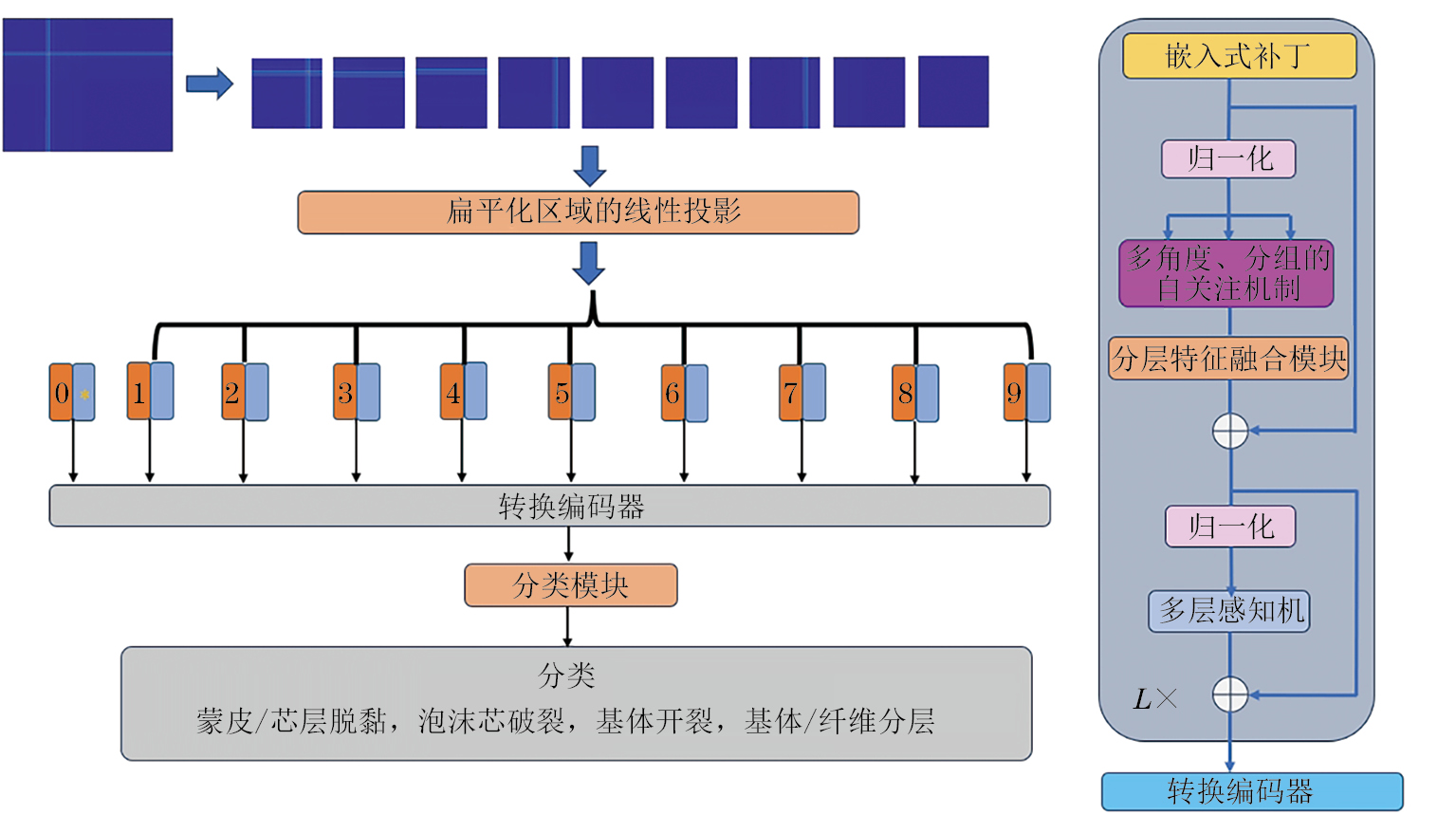
在patch的开头添加了一个额外的科学系嵌入Xclass,其将在训练过程中更新,并生成最终分类结果,为

式中:E为每个补丁x的可训练嵌入先行投影,,;N为patch的数量。
嵌入的patch被输入到12层串行的transformer编码器中,在transformer块中多头注意力机制将输入向量转化为3个向量:一个表示图像patch的查询向量q,一个代表其他所有图像patch的键向量k,以及一个等于q的值的值向量v,它们的维度为dk=dv=dq=dmodel,所有这些向量被堆叠到各自的矩阵Q、K、V中,通过Q和K的缩放点积来计算所有patch之间相对于特定patch的依赖关系。然后再输入到自适应层次特征融合模块(HFF)中对特征进一步融合,该设计使模型能够弥补局部特征获取不足的缺点。在此基础上,MLP的全连接层(FC)将输入尺寸扩大4倍,高斯误差线性单元(GELU)将扩大后的特征尺寸恢复至原始特征尺寸。经过MLP的特征转换处理,转换编码器输出的尺寸与输入的尺寸是一致的,并且可以捕获更加丰富的特征表示。最后再输入到MLP Head(头部)中根据转换编码器提取的特征对相应类别进行分类。模型超参数设置如表1所示。
| 项目 | 参数 |
|---|---|
| 输入图像尺寸 | [224,224,3] |
| Transformer块的数量L | 12 |
| 嵌入向量维度 | 64 |
| 注意力头数量 | 12 |
| 位置编码 | 1D |
2.3 自适应层次特征融合模块
自适应分层特征融合模块(HFF)[9]可以根据输入特征,自适应地融合来自不同层次的局部特征、全局表示和前一层次融合后的语义信息,其中,Gi表示全局特征块生成的特征矩阵,Li表示局部特征块输出的特征矩阵,Fi-1表示前一阶段HFF生成的特征矩阵,Fi表示在这一阶段通过HFF融合生成的特征矩阵。特征融合操作使用式(8)~(12),其结构如图7所示(图中Conv为卷积,GELU为一种激活函数)。

式中:CA为通道注意力机制;SA为自注意力机制;Concat为通道维度;IRMLP为倒残差多层感知机;为元素级相乘;为通过通道注意力组合生成;为通过空间注意力组合生成;为通过前一阶段的HFF模块下采样生成;为全局-局部特征与前一阶段融合的结果。
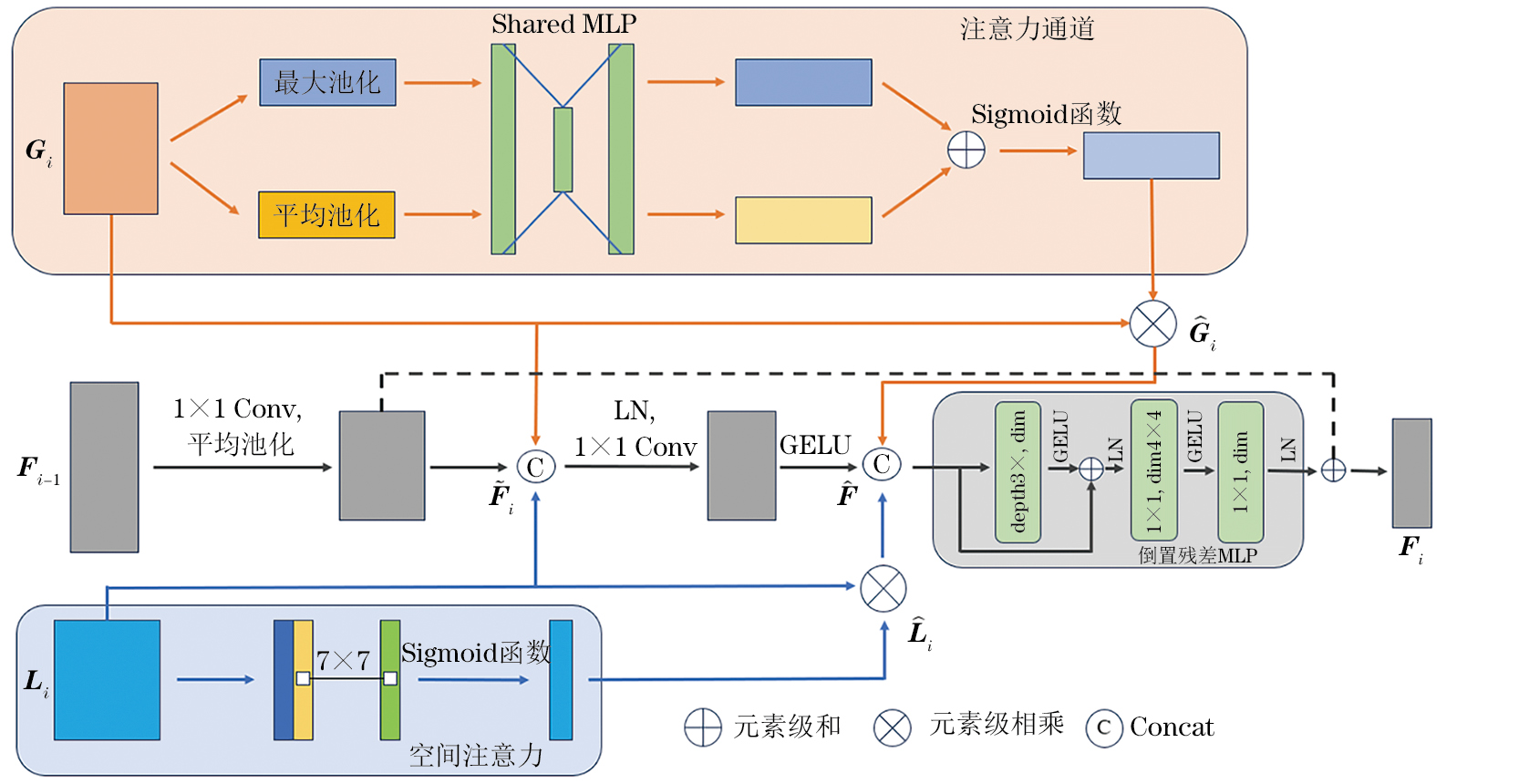
最后将,,进行拼接,并通过IRMLP生成特征。
3. 数据集及模型参数设置
研究了改进的ViT模型对CFRP-PMI夹层复合材料的损伤识别能力,文章所用试验数据为AE系统采集到的声发射波形数据,然后将一维时间序列信号转化为GASF图,形成模型训练数据集,如图8所示。GASF特征图包含了由一维时序信号和特征转换以及合成的信息[10]。ViT模型通过学习特征之间的差异进行分类[11]。
试验在64位Windows10平台上进行,试验使用PYTHON 3.12编程语言和PYTORCH框架。设备信息及训练参数设置如表2所示。
| 类别 | 项目 | 型号及参数 |
|---|---|---|
| 试验条件 | CPU | Intel Core i5-13600KF @3.3 GH |
| 内存/G | 32 | |
| 主板 | Z790 DDR5 | |
| GPU | NVIDIA RTX 4060Ti 16 G | |
| 参数设置 | 学习率 | 0.000 1 |
| 样本数 | 64 | |
| 周期 | 20 |
4. 试验结果分析
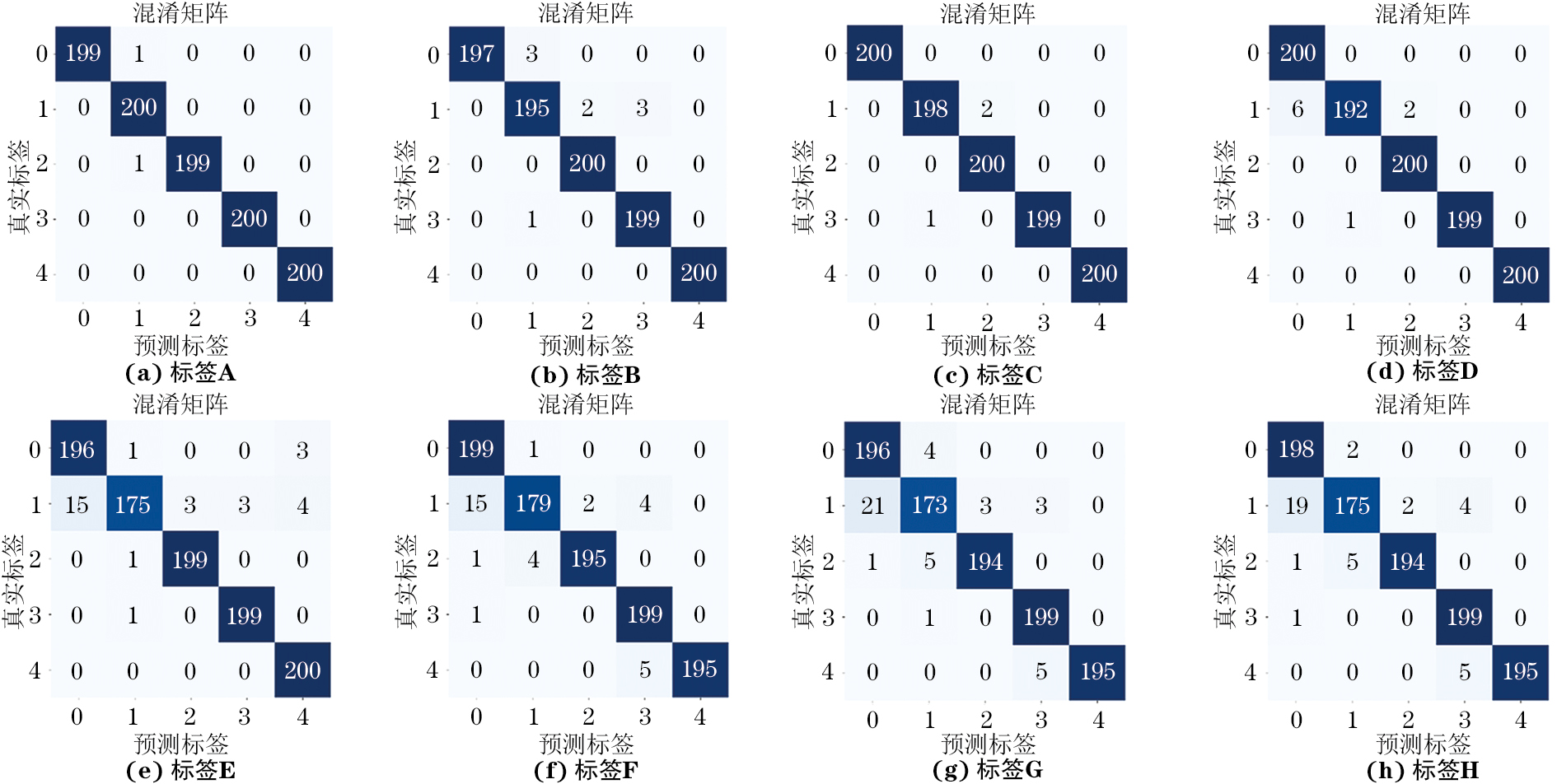
各模型分类准确率对比如表3所示,可见,文章提出的GASF-ViT-HFF模型在测试集中表现出了最高准确率,达到99.8%。即,将HFF模块与ViT结合能够有效提高模型分类的准确率,尤其是在局部特征不明显的情况下,该方法通过特征融合进而提升模型性能。并且,文章将短时傅里叶变换(STFT)频谱图输入到所提出的模型中进行测试,在测试集上的准确率达到96.1%,表现出较好的鲁棒性。在均以GASF图作为输入时,与Efficient network(Efficientnet)、Convolutional next(ConvNeXt)、Class-attention in image transformers(CaiT)以及Convolutional vision transformer(CvT)模型相比,ViT模型表现出卓越的性能,准确率仅低于插入HFF模块的ConvNeXt模型。这是因为HFF模块增强了局部特征融合。试验结果表明,文章所提出的GASF-ViT-HFF模型在CFRP-PMI夹层复合材料的损伤分类任务中表现出优秀的性能,大量的AE波形数据能够使得ViT模型得到充分的训练进而使得分类准确率更高。
| 标签 | 模型 | 输入方法 | 训练精度 | 测试精度 |
|---|---|---|---|---|
| A | ViT-HFF | GASF | 98.6 | 99.8 |
| B | STFT | 94.6 | 96.1 | |
| C | ConvNeXt-HFF | GASF | 95.8 | 97.3 |
| D | ViT | 95.1 | 96.8 | |
| E | ConvNeXt | 92.5 | 92.2 | |
| F | Efficientnet V2-HFF | 83.2 | 85.2 | |
| G | CaiT | 82.3 | 84.9 | |
| H | CvT | 82.1 | 84.5 |
深度学习模型的分类结果和混淆矩阵如图9所示,基于HFF模块改进的ViT模型与其他模型相比能具有更高的对角值[12],仅有两个非对角值(非对角值代表将一个类别错误分类到另一个类别当中),这说明改进后的ViT模型能够在CFRP-PMI夹层材料的损伤分类任务中具有更高的分类精度。
5. 无损检测挂证网结论
针对CFRP-PMI夹层材料损伤分类问题提出了基于改进自适应特征融合模块(HFF)增强Vision transformer(ViT)特征融合分类模型(GASF-ViT-HFF),得出以下结论。
(1)基于GASF-ViT-HFF模型的CFRP-PMI夹层材料损伤分类模型与传统模型和未经改进的模型相比,具有更加优秀的性能,能够有效提高复合材料损伤模式分类精度。
(2)通过使用GASF来增加一维时间序列数据的特征表达取得了显著的效果,其通过计算时间序列点之间的角度关系捕获时间序列的全局特征,进而使得深度学习模型更容易学习关键模式。
(3)对于ViT模型不能够更加详细地捕获细节特征的问题,引入HFF模块来融合多层特征进而增强了对复杂模式的识别能力。
推荐阅读:无损检测挂证价格行情与办理流程详解(2025年12月更新)
